R mlr3 w/ ChatGPT
feat. mlr3
ML in R
![]()
![]()
What is mlr3?
mlr3: Machine Learning in R 3

mlr3 & mlr3verse

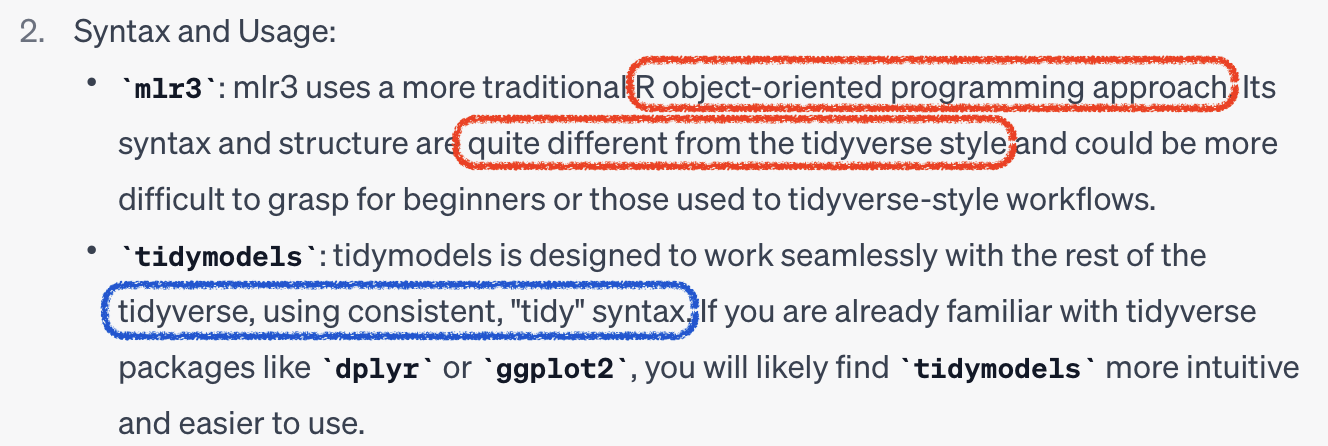
mlr3 vs tidymodels

Core 2. data.table

Utils 3. mlr3viz
ggplot2,autoplot()visualization
Ask ChatGPT!



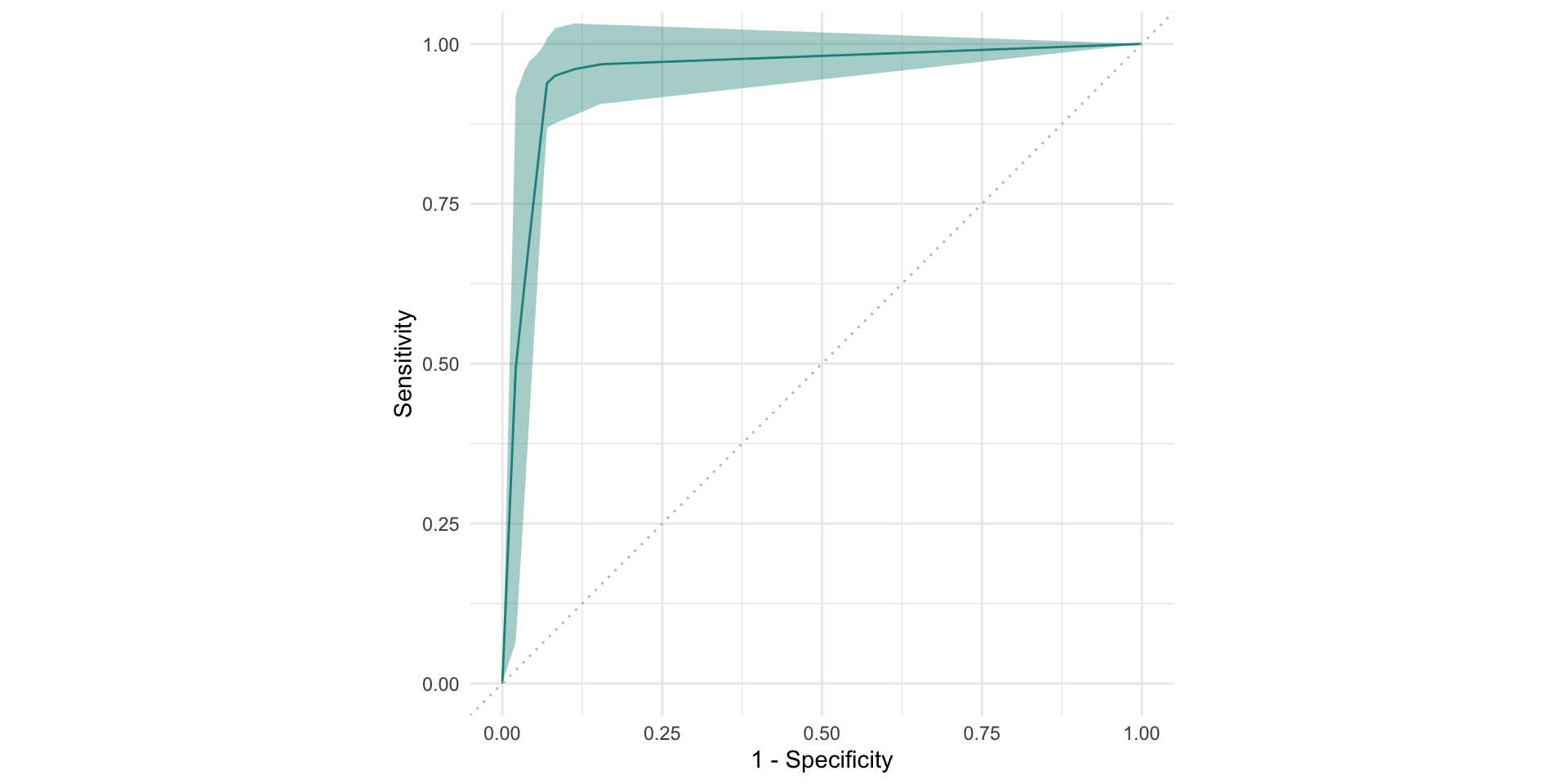
2. Learners
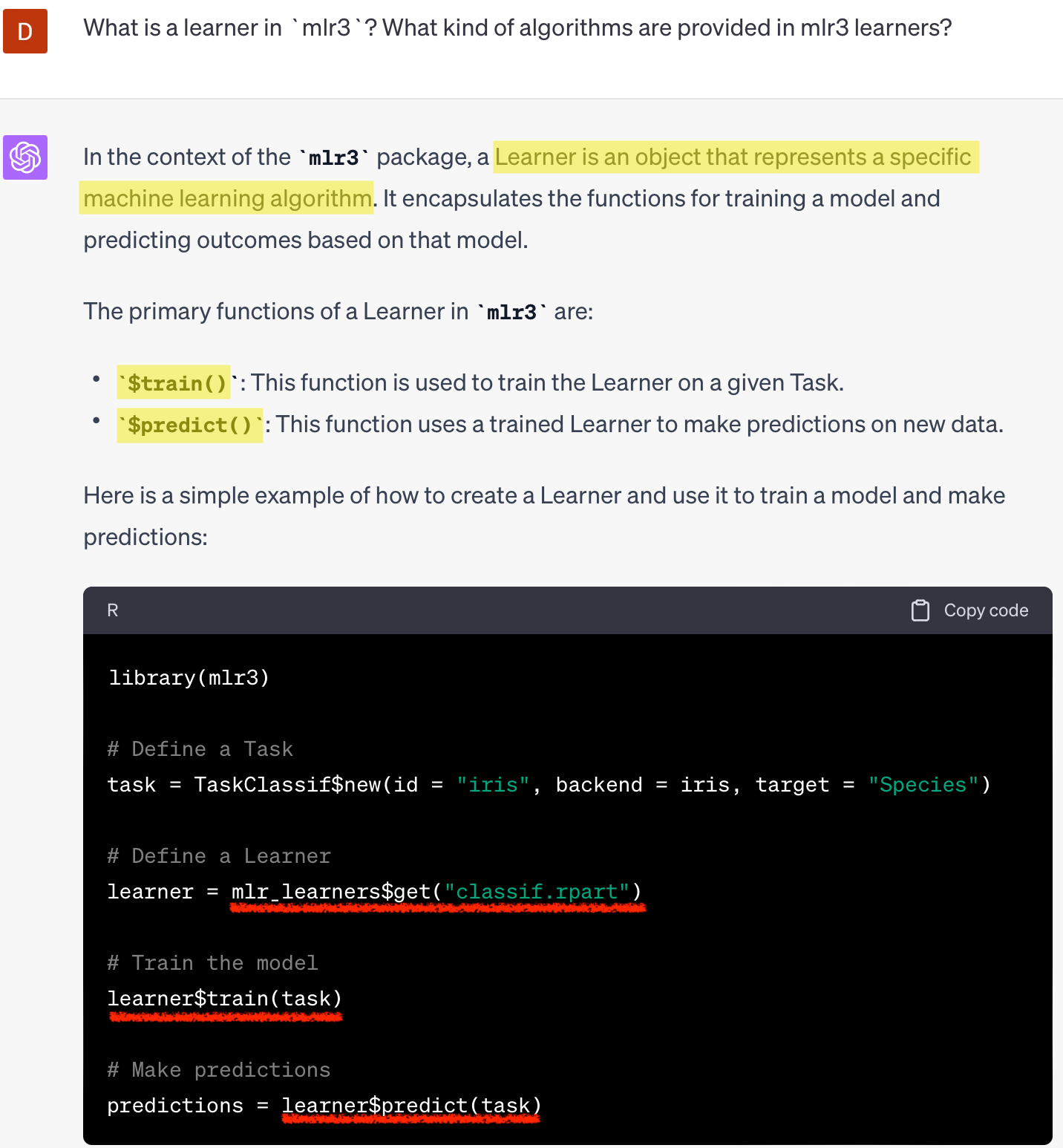
2. Learners
$train(),$predict()

2. Learners
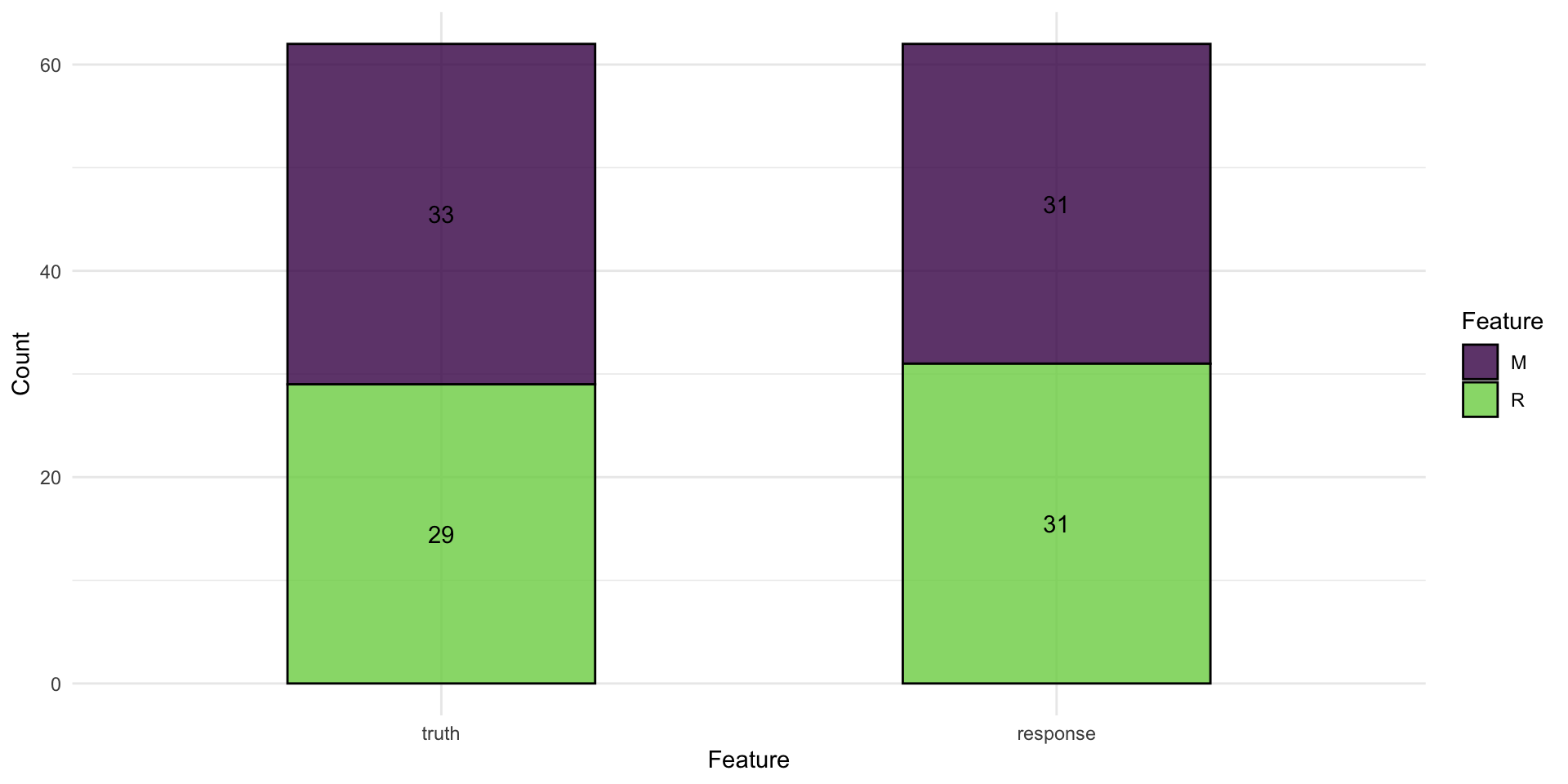
confusion matrix as a bar plot
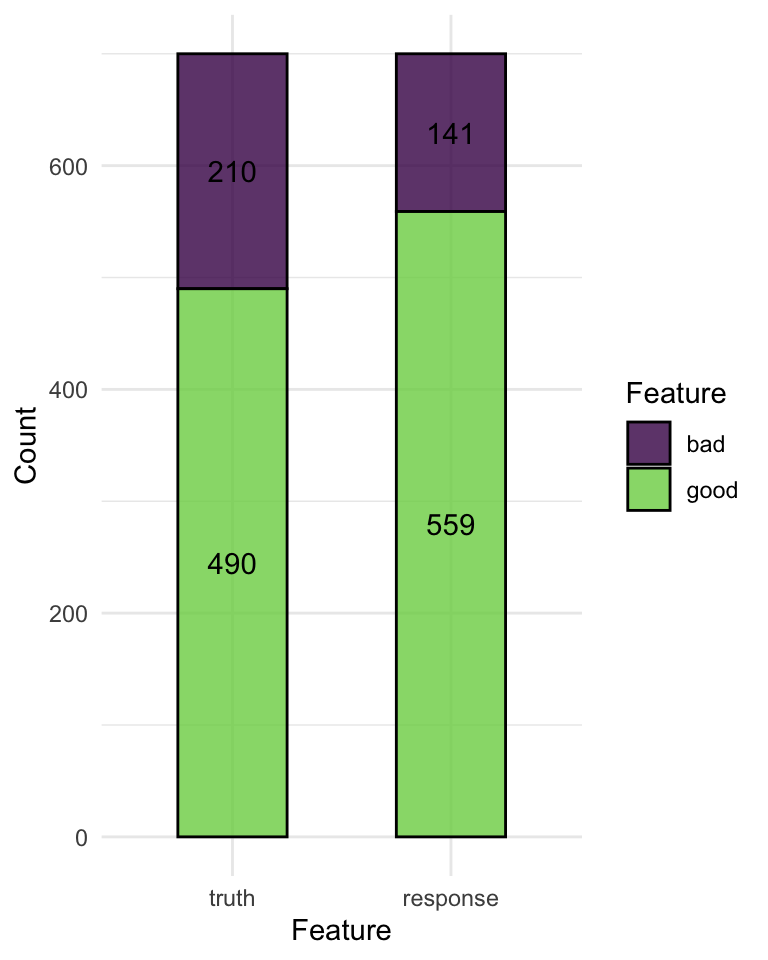
Resampling

- Split available data into multiple training and test sets for generalization
mlr3 vs tidymodels

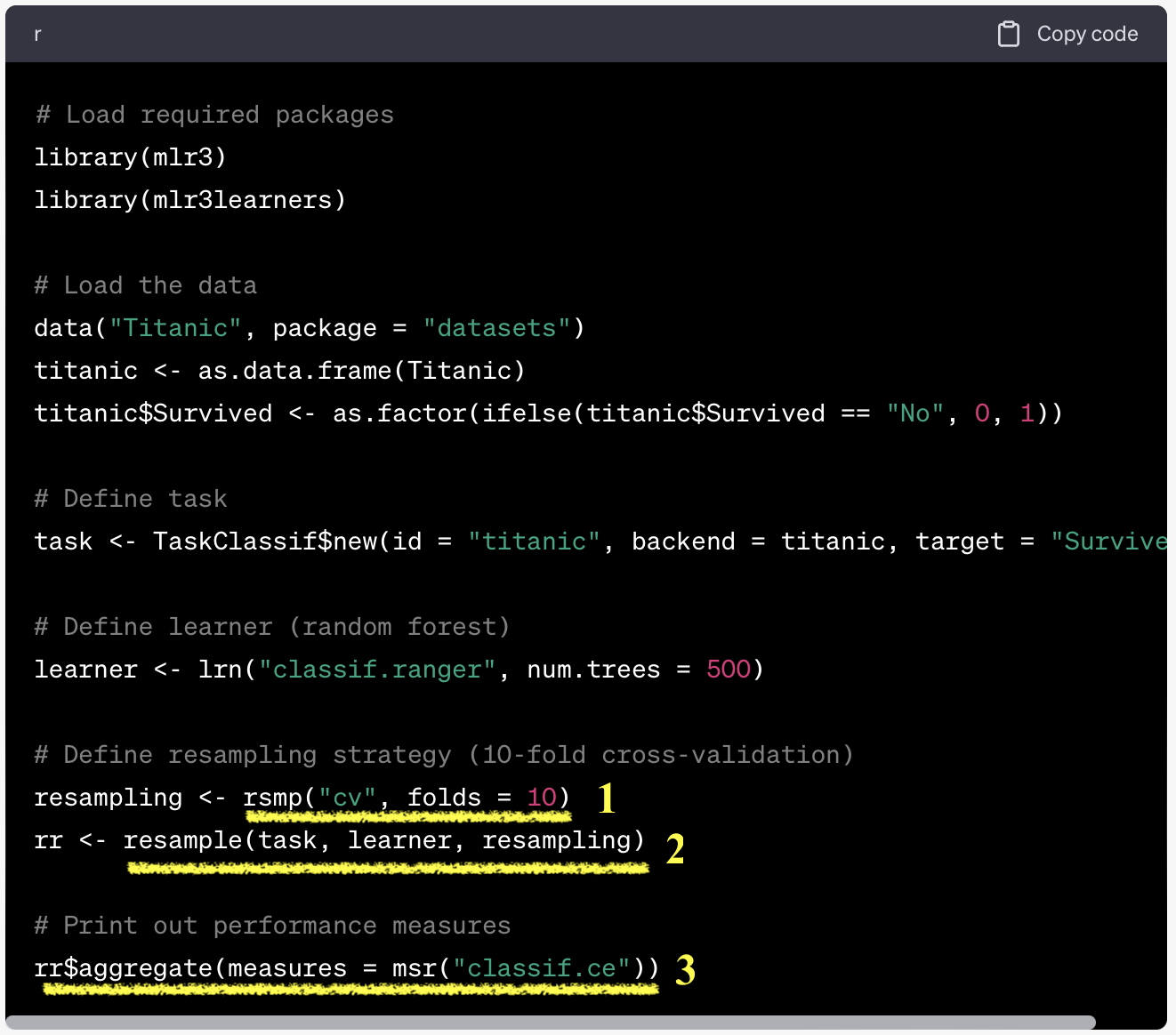
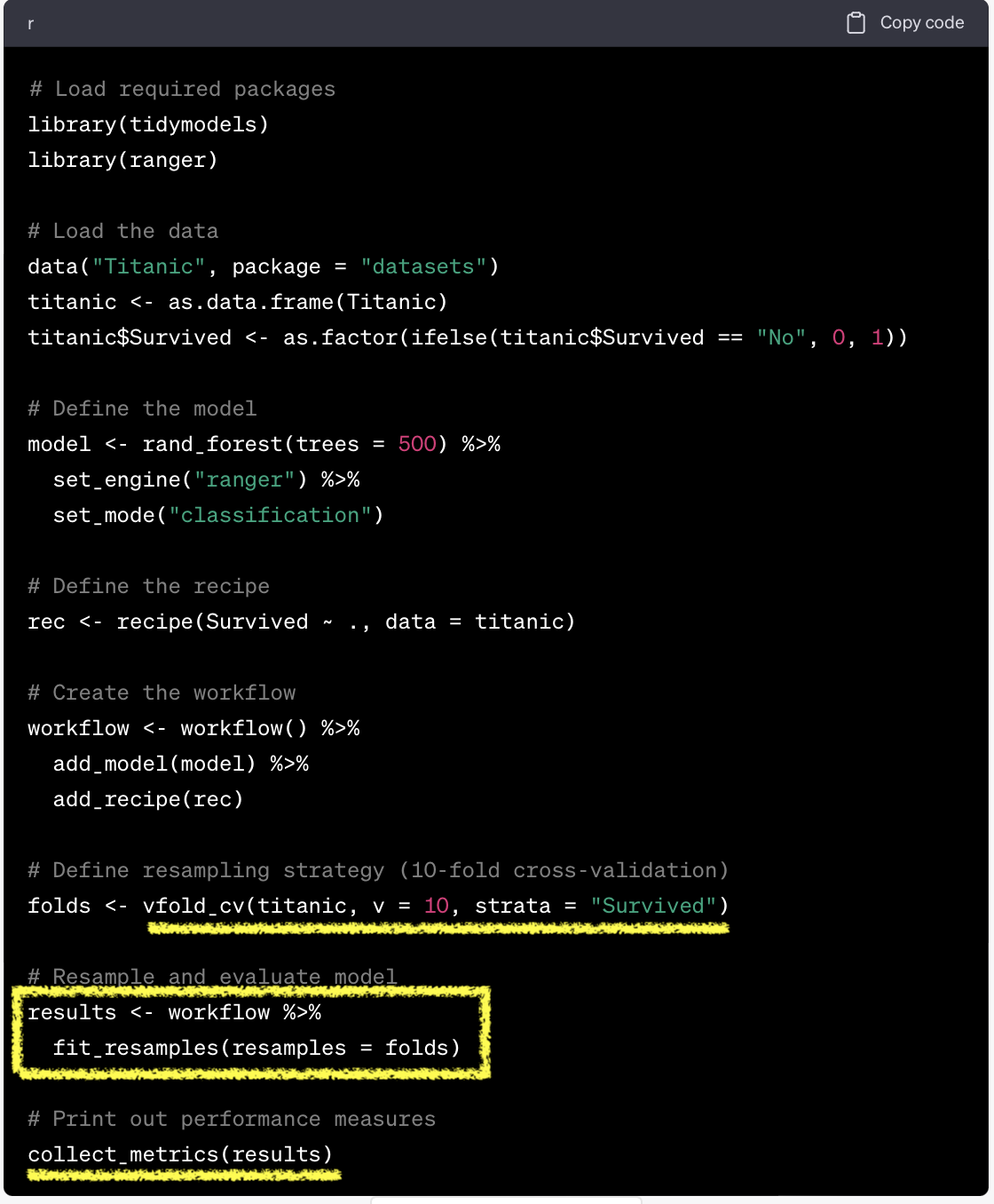
Resampling
plotting resampling results
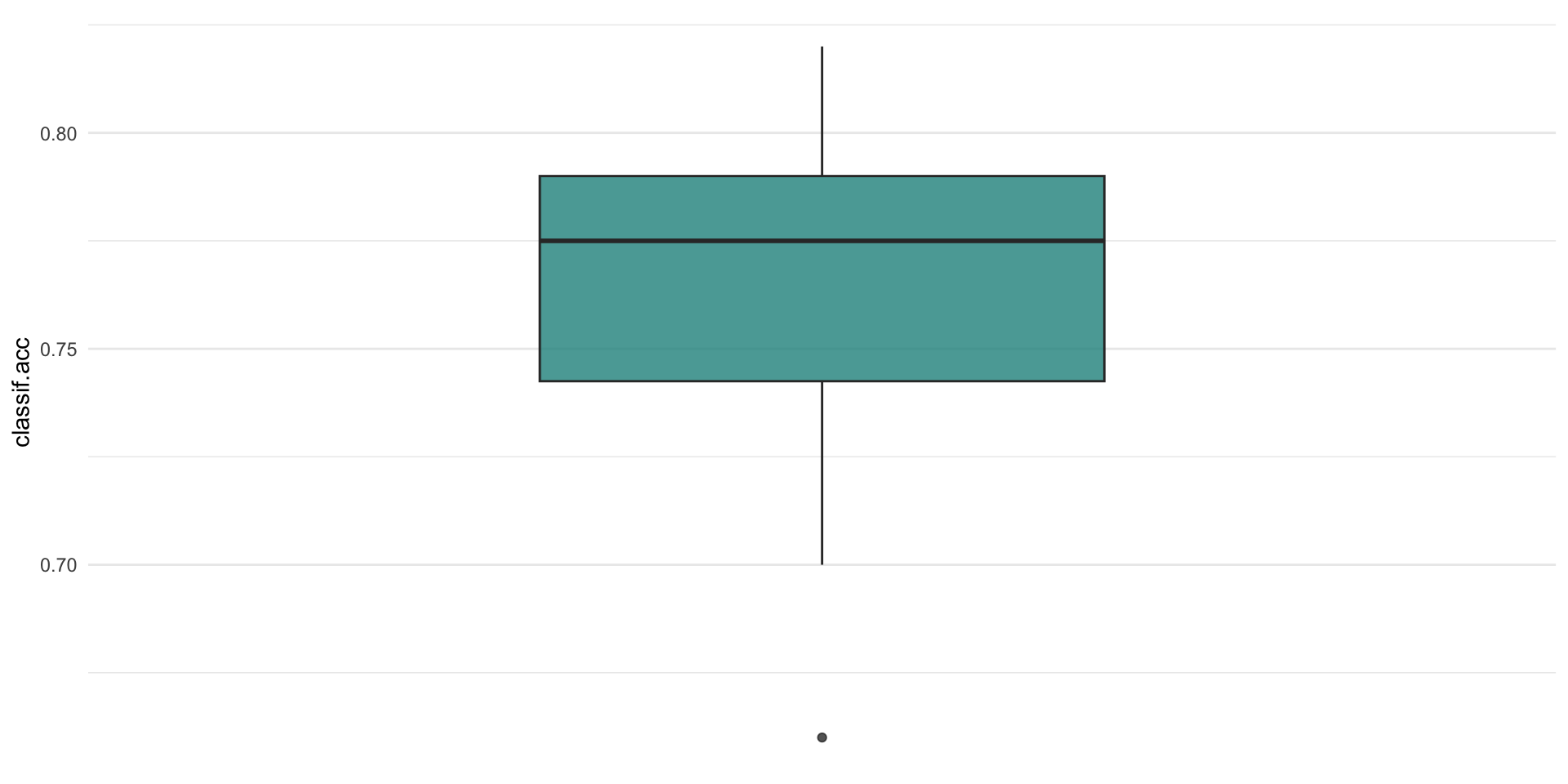
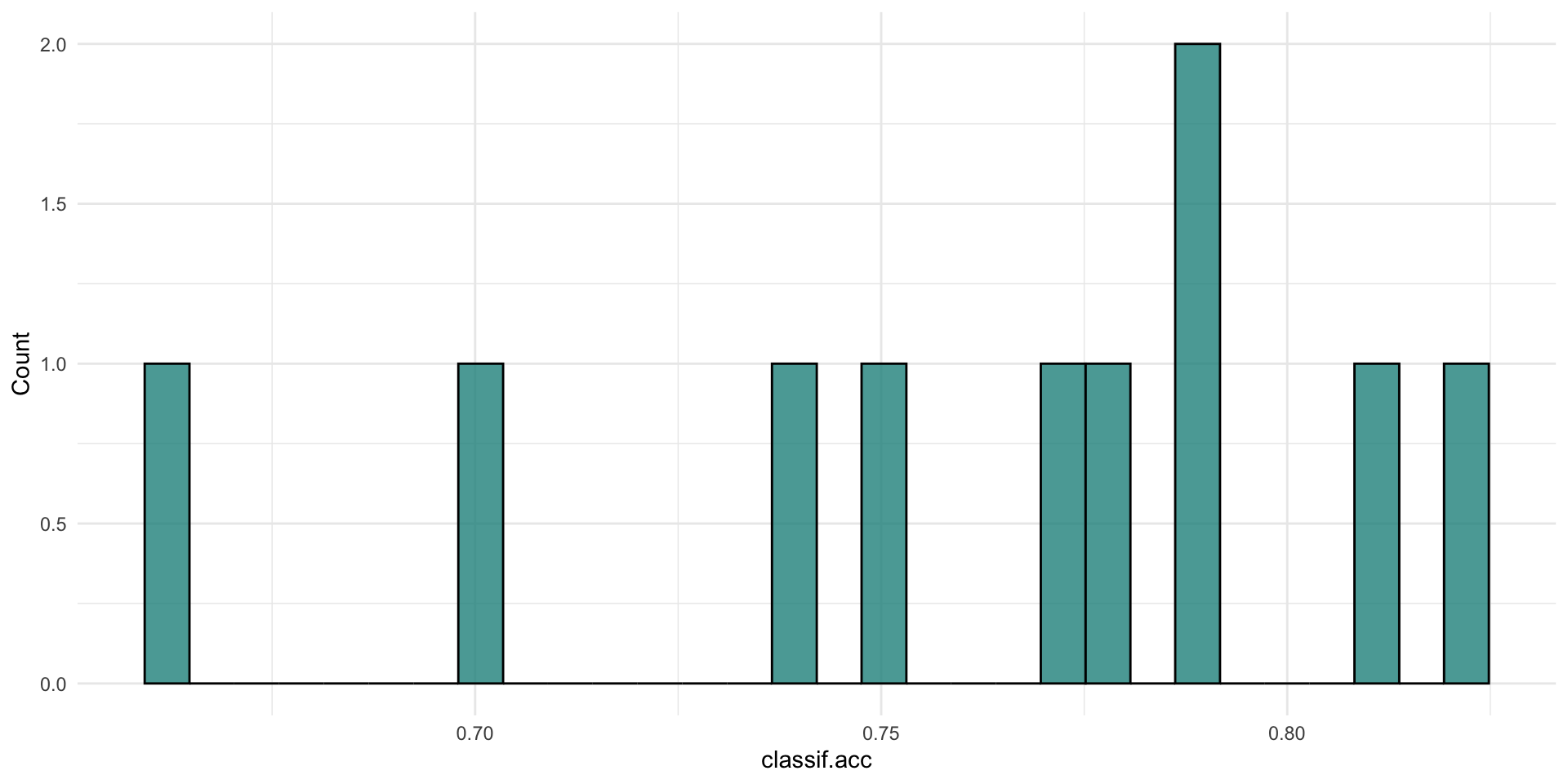
mlr3 vs tidymodels

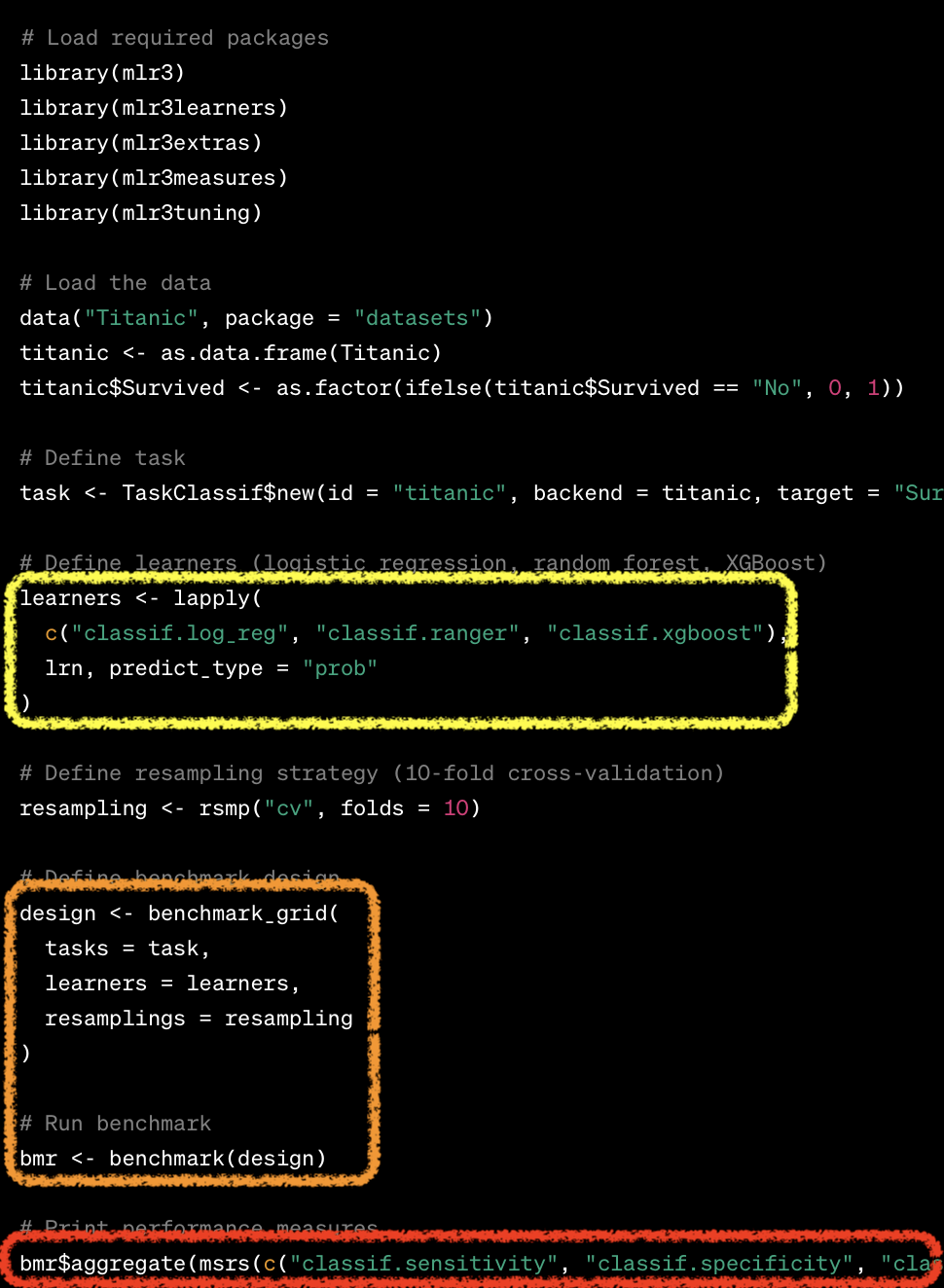
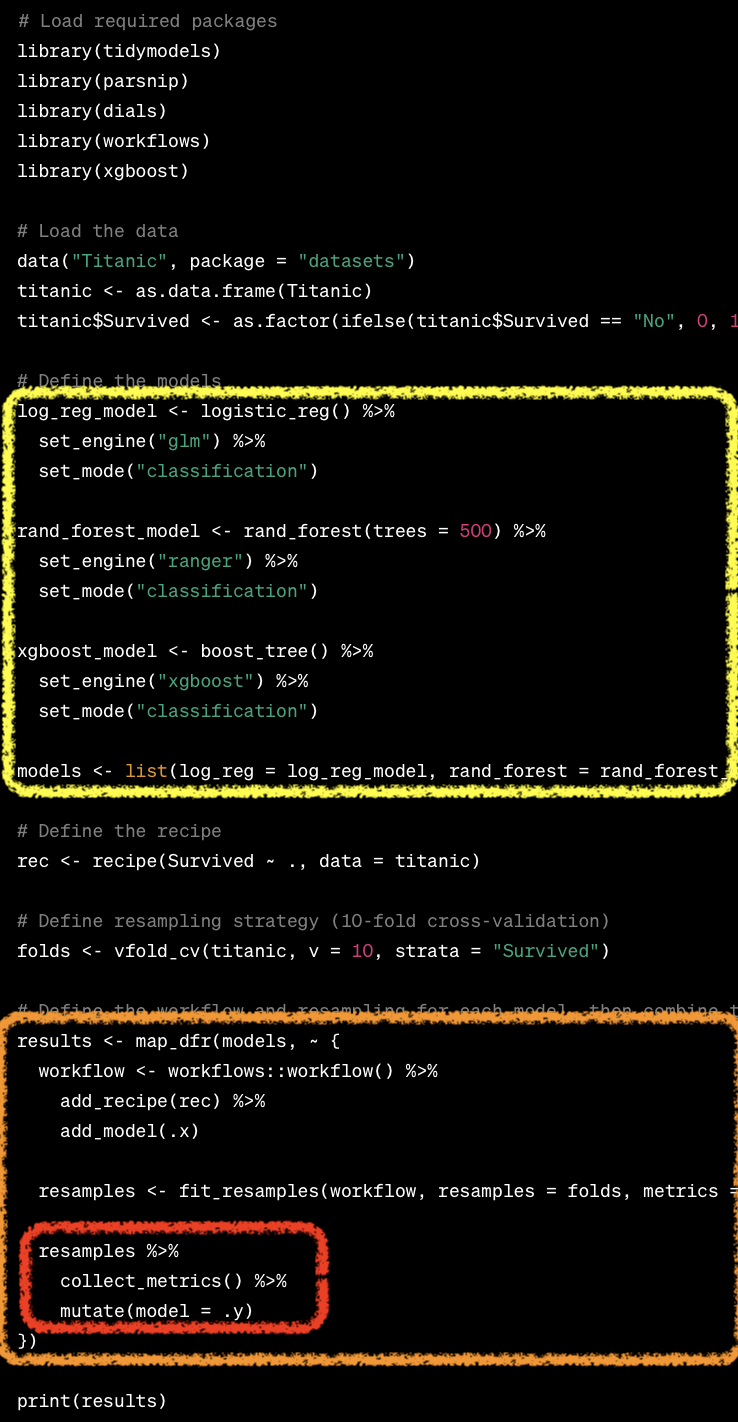
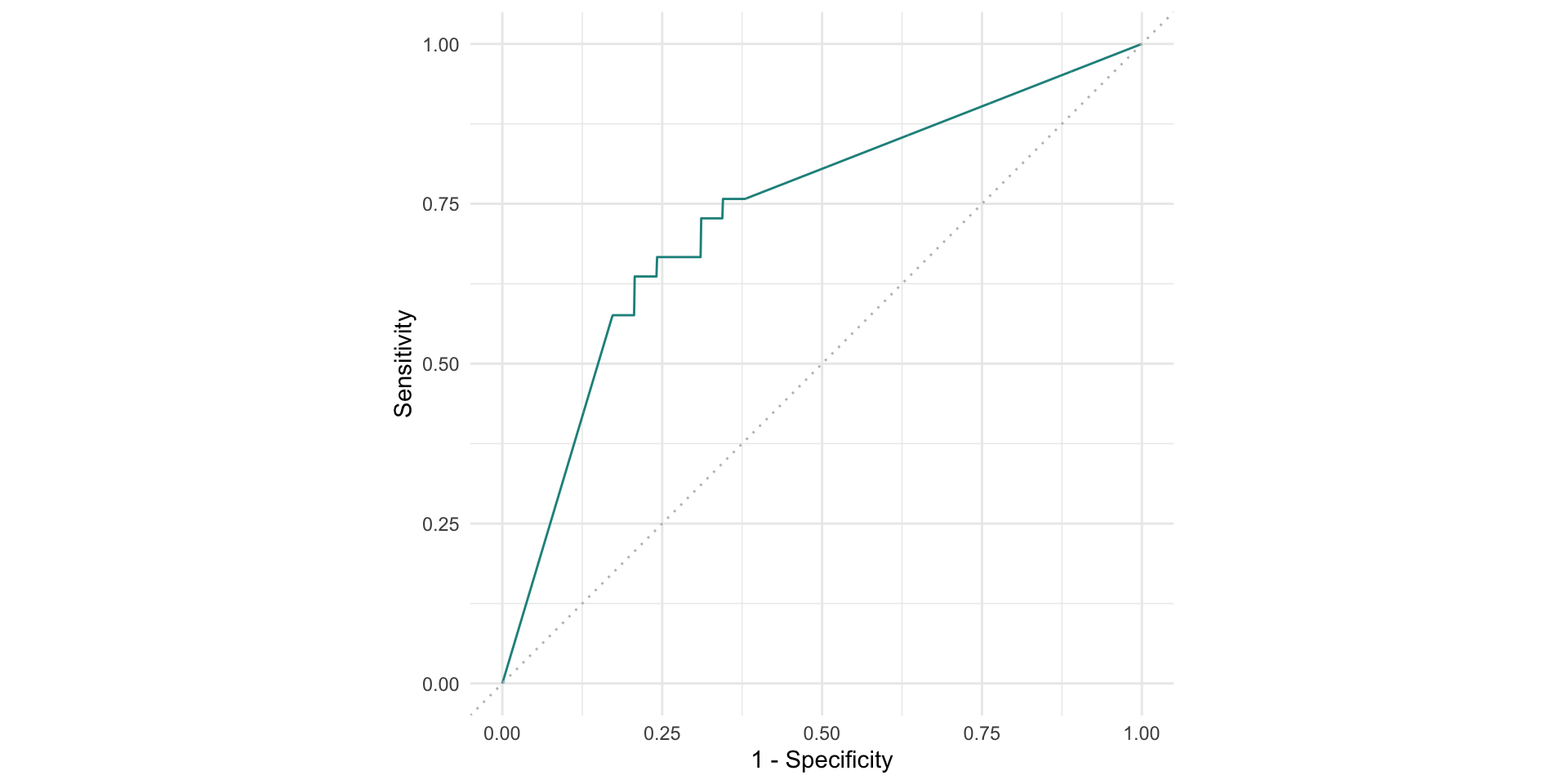
Benchmarking result
task = tsk("german_credit")
learners = list(
lrn("classif.log_reg", predict_type="prob", id = "LR"),
lrn("classif.rpart", predict_type="prob", id = "DT"),
lrn("classif.ranger", predict_type="prob", id = "RF")
)
cv10 = rsmp("cv", folds=10)
design = benchmark_grid(task, learners, cv10)
bmr = benchmark(design)
autoplot(bmr, measure =msr("classif.auc"))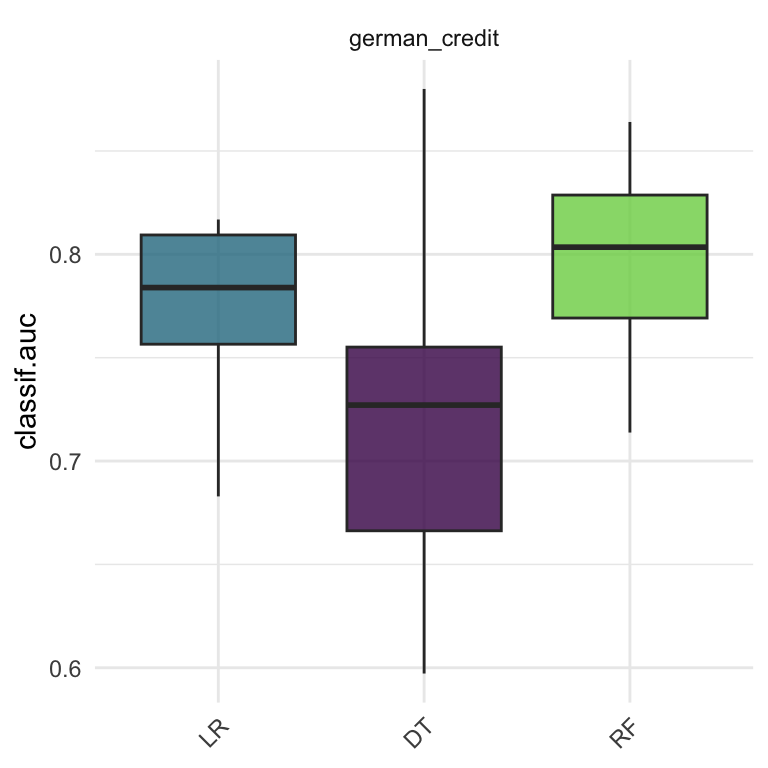
Benchmarking result
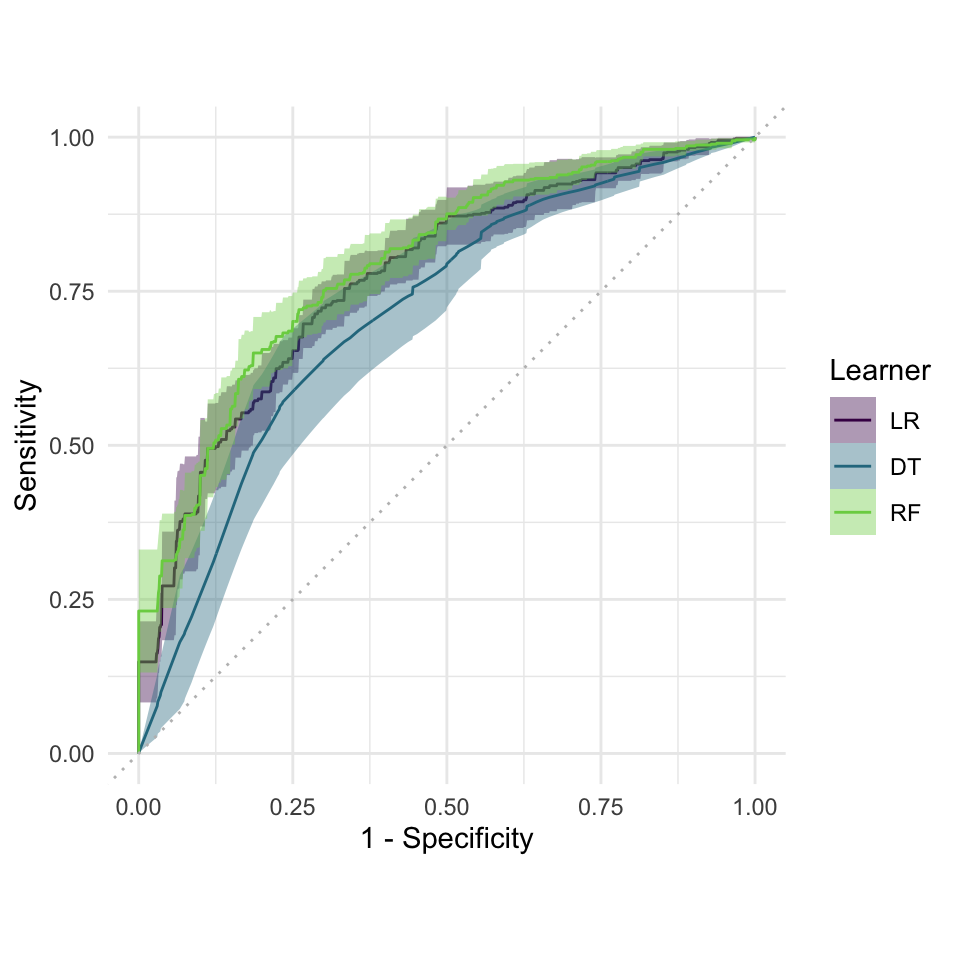
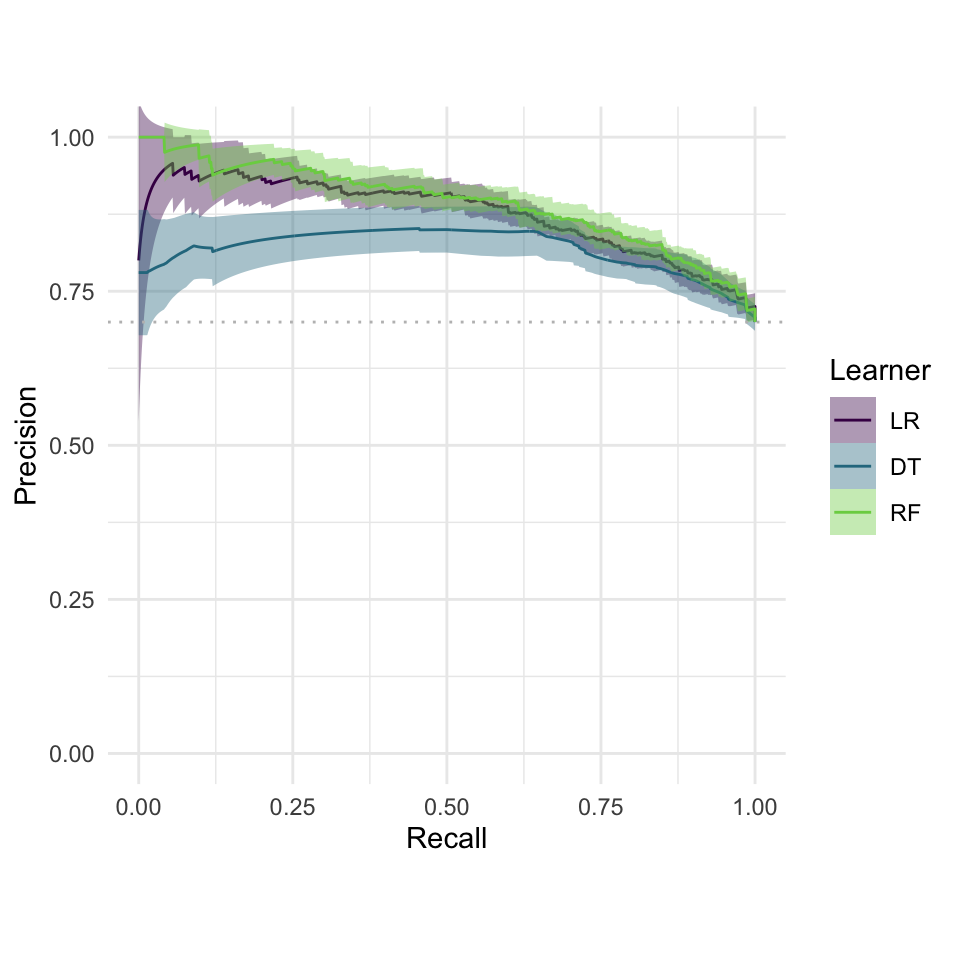
Pipe operator
- Preprocessing with graph construction
- Dictionary:
mlr_pipeops - Sugar function:
po()
<TaskClassif:breast_cancer> (683 x 10): Wisconsin Breast Cancer
* Target: class
* Properties: twoclass
* Features (9):
- ord (9): bare_nuclei, bl_cromatin, cell_shape, cell_size,
cl_thickness, epith_c_size, marg_adhesion, mitoses, normal_nucleoligr = po("scale") %>>%
po("encode") %>>%
po("imputemedian") %>>%
lrn("classif.rpart", predict_type="prob")
gr$plot()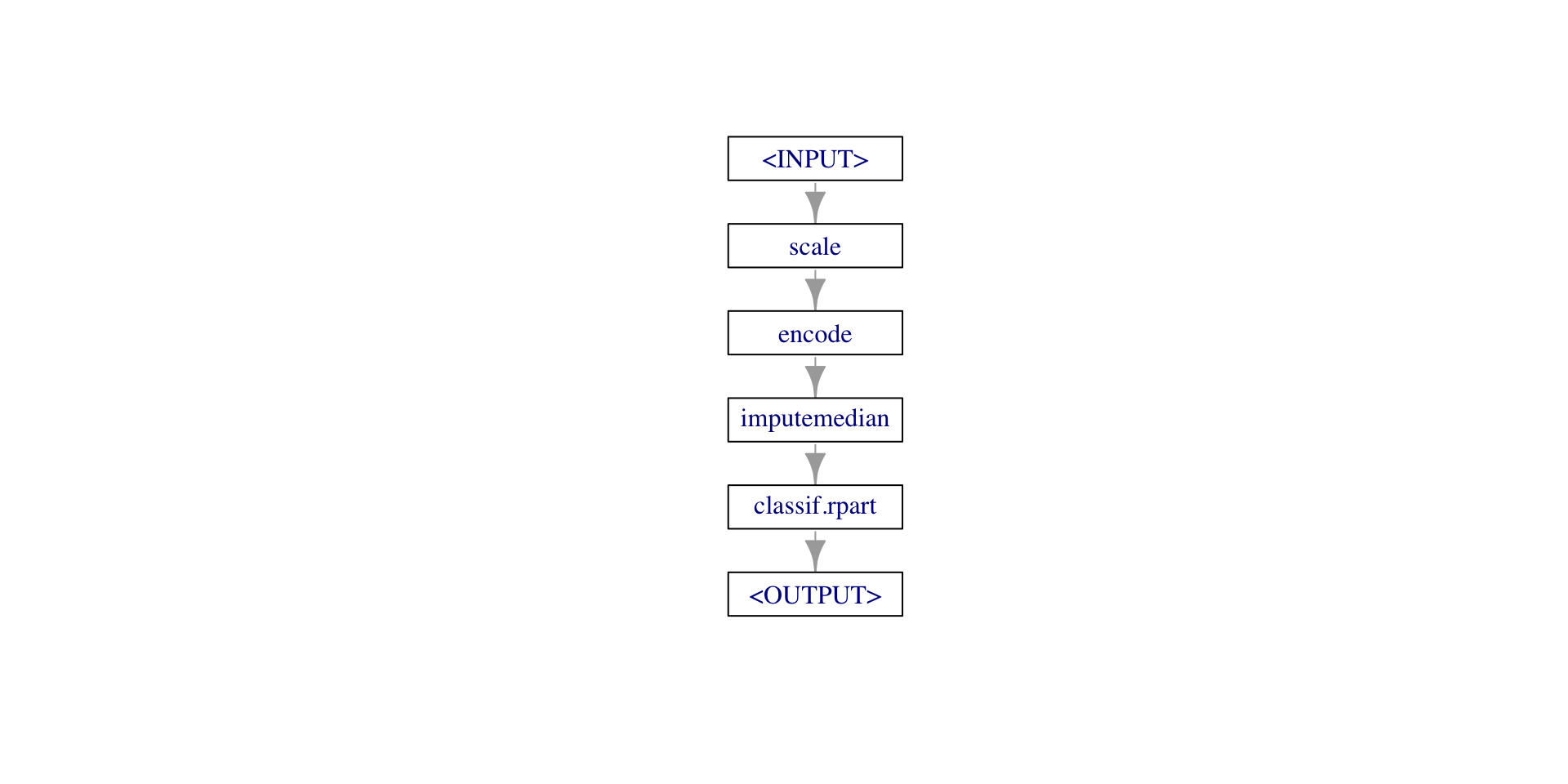
Or manually …
gr = Graph$new()
gr$add_pipeop(po("pca"))
gr$add_pipeop(lrn("classif.ranger"))
gr$add_edge("pca","classif.ranger")
gr$plot()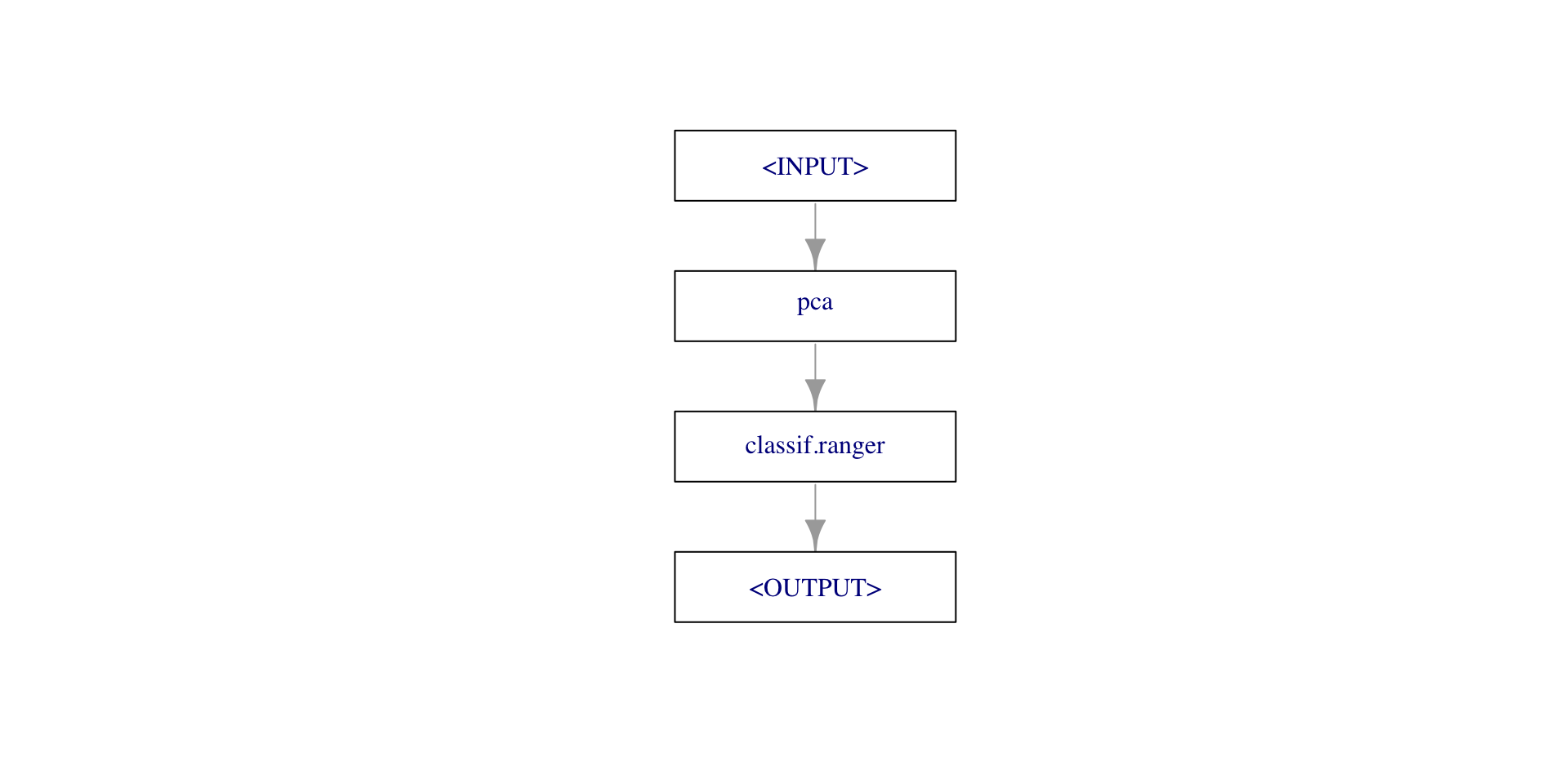
PipeOp: <pca> (not trained)
values: <list()>
Input channels <name [train type, predict type]>:
input [Task,Task]
Output channels <name [train type, predict type]>:
output [Task,Task]