학습공간은 주로 머신러닝 모델 설계자의 경험을 바탕으로 구성되는 것이 일반적입니다. 학습공간과 관련된 자세한 사항은 아래에서 추가적으로 다루도록 하겠습니다.
터미네이터 (Terminator)
앞서 말한 것처럼 이론적으로는 각 러너들의 모든 학습공간을 탐색하며 성능이 가장 뛰어난 모델을 만들 수 있습니다. 하지만 수학적으로, 그리고 현실적으로는 모든 학습공간을 탐색하기란 불가능합니다. 따라서 특정 알고리즘의 하이퍼파라미터 튜닝 과정 도중, 언제 종료할지에 대한 기준 역시 필요합니다.
mlr3tuning 패키지에서는 이것을 Terminator 클래스를 통해 구현해놓았습니다. 터미네이터의 종류는 다음과 같습니다.
Terminator 종류
종 류
설명
사용예시와 초기 파라미터 설정
평가 횟수
특정 탐색횟수가 되면 종료
trm("evals", n_evals= 500)
구동 시간
특정 탐색시간이 되면 종료
trm("run_time", sec= 100)
성능 수준
특정 성능에 도달하면 종료
trm("perf_reached", level= .1)
시간
특정 현실시간이 되면 종료
trm("clock_time", n_evals= 500)
정체
특정 반복동안 개선이 없으면 종료
trm("stagnation", iters= 5, threshold= 1e-5)
조합
여러 터미네이터 조합
trm("combo", terminators = list(run_time_100, evals_200), any = TRUE)
이 중 가장 많이 활용되는 것은 trm("evals", n_evals= 500) 와 trm("run_time", sec= 100) 입니다. trm("combo")는 여러 가지의 터미너이터를 조합하여 종료기준을 설정합니다. any 또는 all을 통해 여러 조건을 하나만 만족해도 종료할지, 모든 기준을 만족해야 할지 설정할 수 있습니다.
ti: 튜닝 인스턴스
튜닝 인스턴스는 어떤 모델을 최적화하기 위해 필요한 모든 정보를 갖는 일종의 환경입니다. 어떤 데이터를 어떤 알고리즘을 통해 학습시킬 건지, 어떤 검증전략을 통해 어떤 성능을 기준으로 파라미터들을 평가할 것인지 등의 정보를 담게 됩니다.
이러한 튜닝 인스턴스는 ti() 함수를 통해 사용자가 직접 설정하거나 tune()을 이용해 자동으로 설정할 수 있습니다. 우선은 ti()를 통해 튜닝 인스턴스를 설정하는 방법부터 알아보겠습니다.
튜닝 인스턴스에는 학습시킬 데이터를 갖고 있는 태스크(task), 러너(learner), 리샘플링 (resampling), 성능 측정(measure), 그리고 터미네이터(terminator)가 사용됩니다.
grid search와 random search는 가장 기본적이면서도 많이 사용되는 튜닝 알고리즘입니다. grid search는 학습공간에서 설정한 범위 내의 모든 하이퍼파라미터를 평가하는 반면, random search는 랜덤하게 학습공간을 탐색하여 하이퍼파라미터들을 평가합니다.
grid search와 random search는 나이브(naive)한 알고리즘으로 평가받는데, 이는 하이퍼파라미터들을 평가할 때, 이전 평가값들을 무시하고 새롭게 하이퍼파라미터들을 구성하기 때문입니다.
반면에 Covariance Matrix Adaptation Evolution Strategy (CMA-ES)나 베이지안 최적화와 같은 보다 정교한 알고리즘들은 모델 기반 최적화라고도 볼립니다. 이 알고리즘들은 하이퍼파라미터 평가 과정 중 이전의 평가된 구성으로부터 학습하여 더 좋은 하이퍼파라미터 조합을 더욱 빠르게 찾아냅니다.
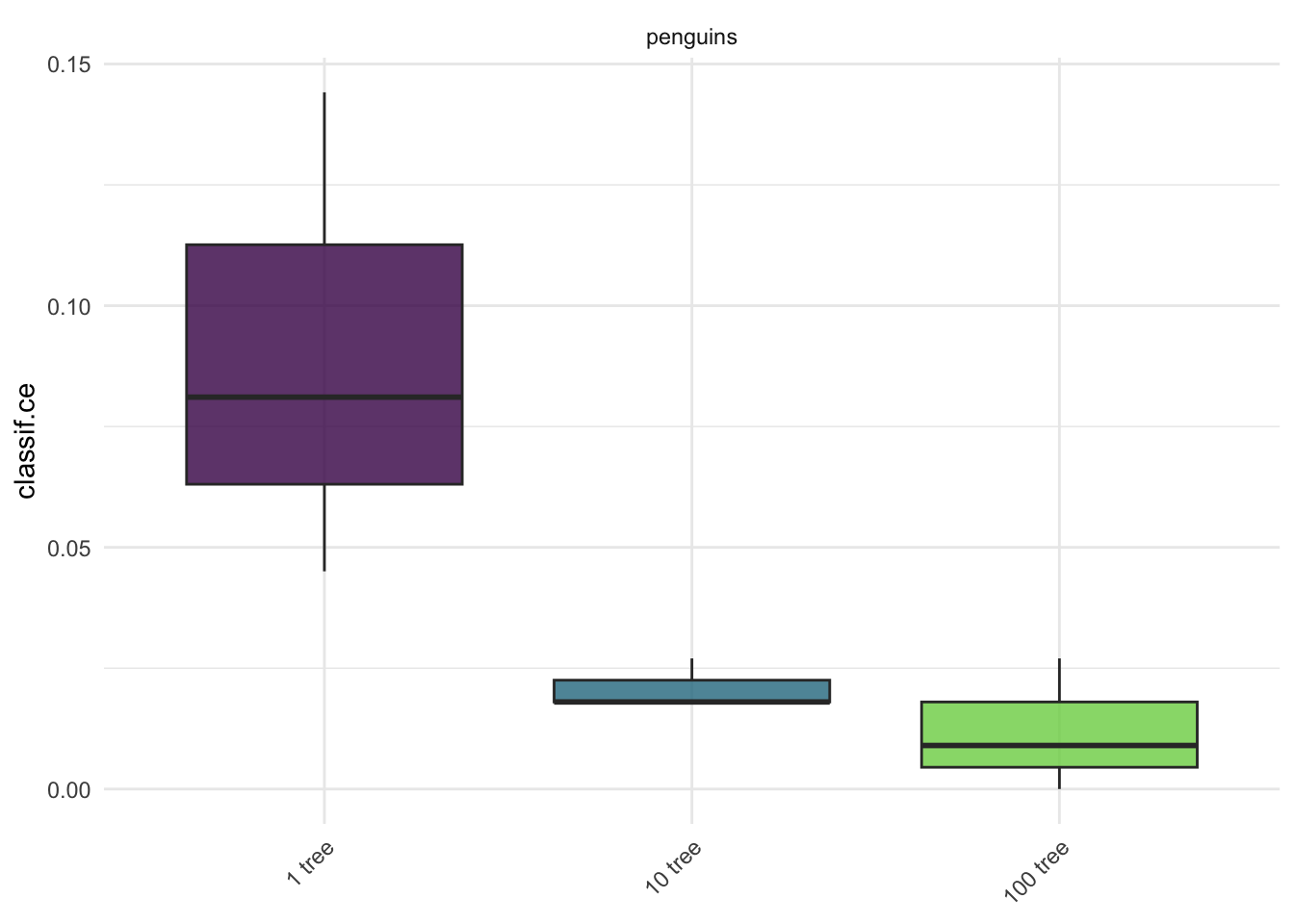
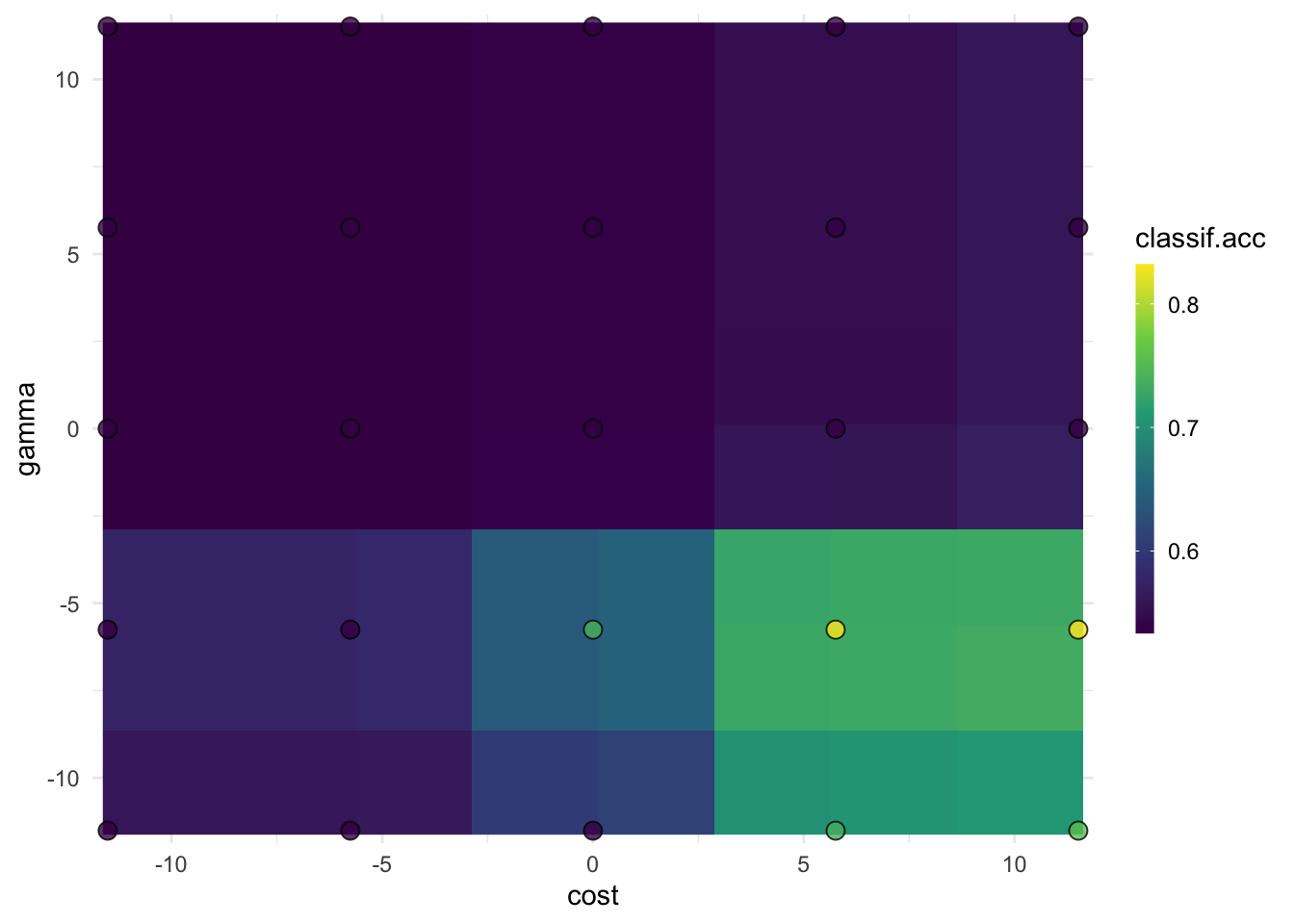
앞서 우리가 만들었던 SVM 알고리즘을 튜너를 활용해 하이퍼파라미터를 탐색해보도록 하겠습니다. tnr() 함수를 이용해 튜닝을 수행하는데, batch_size를 설정하여 한 번에 몇 개의 하이퍼파라미터 구성을 평가할지 설정할 수 있습니다. 이 때 설정해주는 resolution의 경우 하이퍼파라미터 조합의 숫자와 연관이 있습니다. 예를 들어 위의 튜닝 인스턴스에서 범위를 정해준 하이퍼파라미터는 두 개 (cost, gamma)입니다. resolution을 5로 설정할 경우 \(5^2=25\), 즉 25번의 하이퍼파라미터 조합이 구성되는 것입니다.
하이퍼파라미터 최적화는 모델 성능 측정 시 발생할 수 있는 편향을 예방하기 위해 추가적인 리샘플링이 필요합니다. 만약 동일한 데이터가 최적의 하이퍼파라미터를 구성하고 모델링 결과를 평가하는 데 사용된다면 매우 심하게 편향이 있을 수 있습니다.
중첩 리샘플링은 추가적인 리샘플링을 수행함으로써 튜닝된 모델의 성능을 평가하는 과정에서 모델 최적화를 분리시켜 놓습니다. 즉 일반적인 방법의 리샘플링 방법으로 모델의 성능을 평가하는 반면, 튜닝의 경우 리샘플링된 데이터를 다시 리샘플링하여 성능을 평가하는 것입니다.
위의 그림은 중첩 리샘플링의 예시를 잘 보여주고 있습니다.
외부 리샘플링: 각기 다른 훈련, 검증 데이터셋을 만들기 위한 3-fold 리샘플링
내부 리샘플링: 외부 리샘플링 안에서 하이퍼파라미터 튜닝을 위한 4-fold 리샘플링
하이퍼파라미터 최적화: 내부 리샘플링 데이터를 활용한 외부 훈련 데이터셋의 하이퍼파라미터 최적화
모델 학습 (Training): 가장 하이퍼파라미터 최적화가 잘된 외부 학습 데이터셋을 활용해 모델 학습
모델 평가 (Evaluation):
교차 검증 (Cross validation): 2~5번 과정을 각 3 fold에서 반복
집계 (Aggregation): 리샘플링의 성능을 집계하여 평가
중첩 리샘플링은 컴퓨팅 계산이 굉장히 많이 필요합니다. 위에서 예로 들었던 3-fold 외부 리샘플링과 4-fold 내부 리샘플링, 그리고 grid search를 통한 2가지 파라미터를 5개의 resolution 조합으로 구성할 시, \(3*4*5^2 = 300\)번의 모델 학습 및 검증이 이루어지게 됩니다.
AutoTuner를 활용한 중첩 리샘플링
mlr3에선 AutoTuner를 활용한다면 중첩리샘플링도 쉽게 수행이 가능합니다. 코드를 통해 중첩 리샘플링을 살펴보겠습니다.
AutoTuner 내부에서 수행하는 리샘플링은 inner resampling으로 4-fold 교차 검증을 수행합니다. 반면에 at를 대상으로 수행하는 resample()의 경우 outer resampling으로 3-fold 교차 검증을 수행합니다.
외부 리샘플링의 일부 결과에서 확연히 낮은 성능이 나온다는 것은 최적화된 하이퍼파라미터가 데이터에 과적합되었다는 것을 의미합니다. 따라서 튜닝된 모델은 요약계산된 성능으로 보고하는 것이 중요합니다.
rr$aggregate()
classif.ce
0.2255349
마지막으로 중첩 리샘플링을 과도하게 많이 설정하는 경우, 컴퓨터 성능을 많이 필요로 하게 됩니다. 예를 들어 위의 예시에서는 내부 리샘플링 4, 외부 리샘플링 3, 하이퍼파라미터 2개, resolution 5로 인해 \(3*4*5*5=300\), 즉 300번의 모델 훈련 검증을 수행하게 됩니다. 따라서 내부 리샘플링에서는 홀드아웃 등과 같은 방법을 사용하거나 병렬화를 사용하도록 하는 것을 권장합니다.
R6 Class
Sugar function
요약
Tuner
tnr()
최적화 알고리즘 결정
Terminator
trm()
튜닝 알고리즘 종료 시점 기준 설정
TuningInstanceSingleCrit or TuningInstanceMultiCrit
 위의 그림은 중첩 리샘플링의 예시를 잘 보여주고 있습니다.
위의 그림은 중첩 리샘플링의 예시를 잘 보여주고 있습니다.