head(df)인트로: 개념의 차이
Alluvial plot과 Sankey plot은 데이터의 흐름을 시각화하는 데 사용되는 그래프 중 하나입니다.
두 그래프는 겉으로 보기에는 비슷하면서도, 명확히 다른 점을 갖고 있습니다. 우선 두 그래프의 예시부터 살펴보도록 하겠습니다.
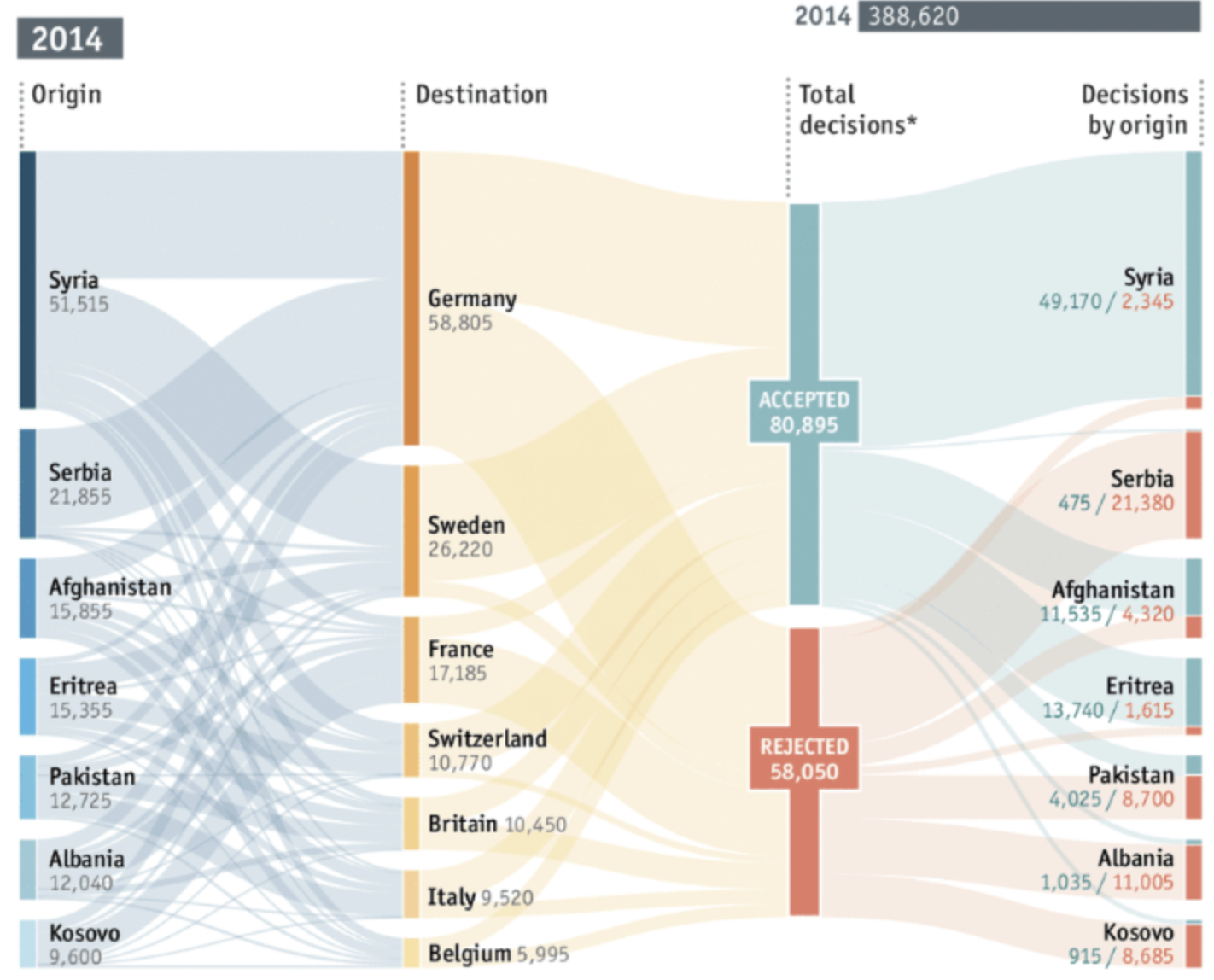
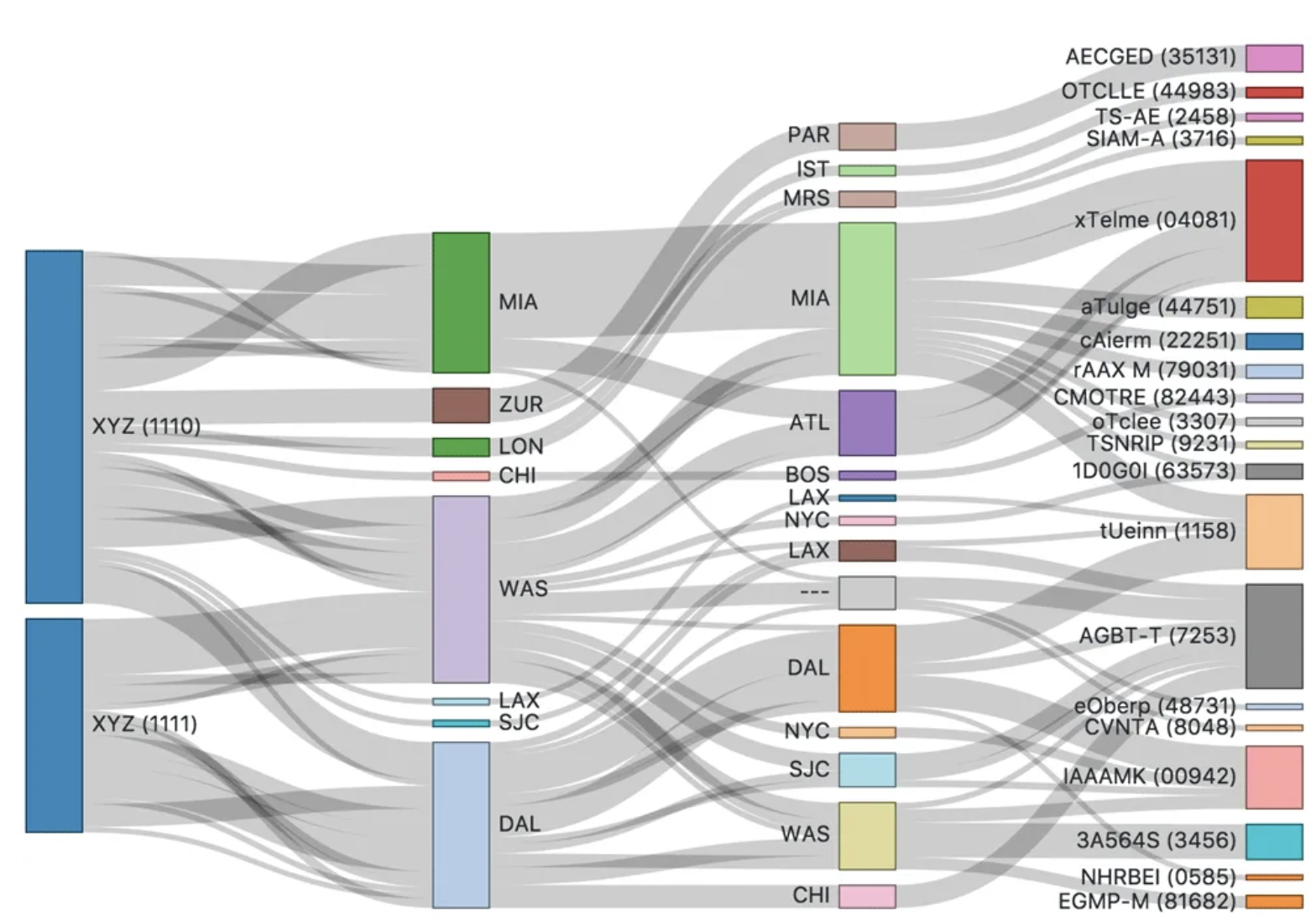
공통점
겉으로 보기에는 두 그래프가 비슷합니다. 예를 들어
- 두 그래프 모두 노드와 여러 범주로 이루어진 수직 막대가 존재합니다.
- 노드 간에 두께와 높이가 각각 다른 곡선으로 연결되어 있습니다.
이러한 점들 때문에 두 그래프를 혼동하고는 합니다.
그러나 두 그래프 간에는 명확한 차이점이 존재합니다.
Alluvial plot
먼저 Alluvial plot의 특징은 다음과 같습니다.
- 특정 집단에 소속된 사람들이 다양한 범주차원에서 어떻게 구성되는지를 보여줍니다.
- 범주를 나타내는 막대의 위치가 크게 상관없습니다.
- 특정 사람들이 어떤 특징을 가지고 있는지 보여주는 데 적합합니다.
Sankey diagram
반면 Sankey diagram은 다음과 같은 특징을 갖습니다.
- 특정 데이터의 양이 어떻게 흐르는지, 어떻게 변화하는지를 보여줍니다.
- 범주를 나타내는 막대의 배치에 따라 시간의 흐름을 나타냅니다.
- 어떤 데이터의 양, 크기, 또는 사람들의 흐름이나 과정을 시각화하는 데 적합합니다.
이렇게 두 그래프의 개념적인 차이에 대해 살펴보았습니다.
우리가 다룰 패키지는 비록 alluvial이 들어가지만, 어떤 데이터를 어떻게 표현는지에 따라 Alluvial plot이 될 수도 있고, Sankey diagram이 될 수도 있다는 것을 말씀드리고 싶습니다.
그럼 지금부터 Alluvial 또는 Sankey plot을 그리는 방법을 패키지를 통해 말씀드리겠습니다.
alluvial 패키지를 이용한 시각화
alluvial 패키지를 이용해 시각화를 진행해보겠습니다. 해당 데이터는 제가 연구하던 패혈증 데이터입니다.
ICU에 입원한 환자들의 일자별 AKI stage 상태의 변화를 시각화하는 그래프입니다.
library(alluvial)
alluvial(TZ=df$AKI_initial,
`Day 1` = df$AKI_status_day1,
`Day 2` = df$AKI_status_day2,
`Day 3` = df$AKI_status_day3,
`Day 7` = df$AKI_status_day7,
freq=df$N,
col = ifelse(df$AKI_stage == 'Stage 1','#00AFBB',
ifelse(df$AKI_stage == 'Stage 2','#E7B800',"#FC4E07")),
alpha=.8
)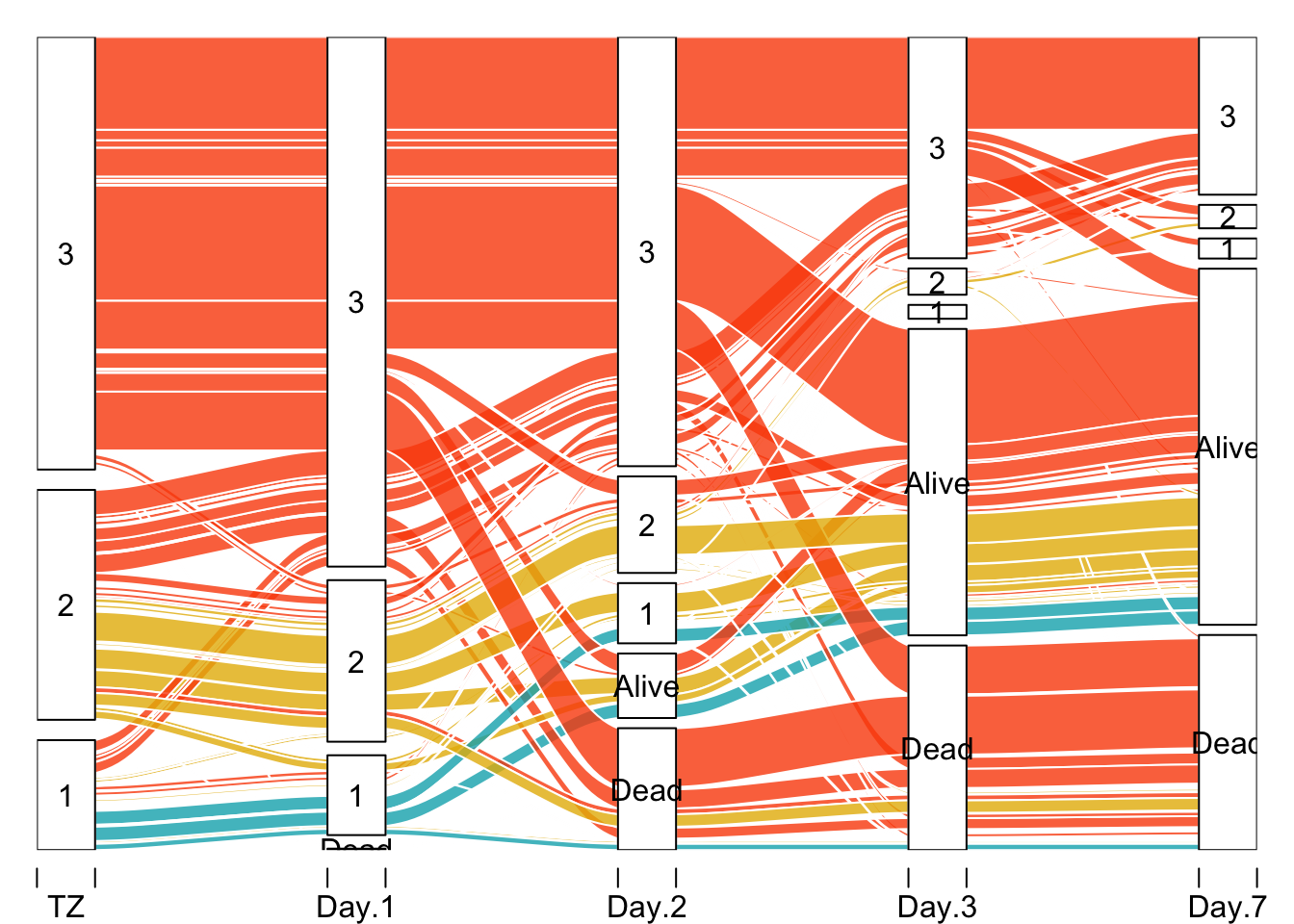
이 그래프는 일자별로 환자들의 상태가 어떻게 변화되는지를 나타내기 때문에, Sankey diagram으로 분류됩니다.
alluvial()사용법은 굉장히 간단합니다. 막대별로 들어갈 변수를 입력해준 뒤, 각 경우별 빈도를 뜻하는 column을 freq에 넣어주면 됩니다.
색상은 col에서 설정 가능합니다.
ggalluvial 이용
R에서 Sankey plot을 시각화할 수 있는 패키지 중 또 다른 하나는 ggalluvial 입니다. gg가 붙은 것에서 알 수 있듯이, ggplot2 의 확장 패키지 중 하나입니다.
저 같은 경우, 시간의 흐름에 따른 범주의 양상을 Sankey plot으로 시각화한 경험이 있습니다. 예를 들면 첫 번째 건강검진부터 세 번째 건강검진 간 비만인 사람들의 분포를 시각화하는 것이죠.
ggalluvial은 Sankey plot을 그리기 위해 wide 데이터와 long 데이터를 모두 사용할 수 있습니다.
Wide 데이터로 Sankey plot 그리기
wide 데이터는 쉽게 말해 여러 가지 column이 옆으로 붙어있는 데이터를 의미합니다.
Sankey plot을 그리기 위한 wide 데이터에서는 하나의 열에 범주가 와야 하고, 범주의 조합에 해당하는 빈도(Frequency) 열이 와야 합니다.
예를 들어 HairEyeColor 데이터를 살펴보겠습니다.
HairEyeColor |> as.data.frame() HairEyeColor 데이터는 성별, 머리 색상, 눈동자 색상에 따른 빈도 데이터를 담고 있습니다. 이 데이터를 활용해 Sankey plot을 작성해보도록 하겠습니다.
library(ggalluvial)
ggplot(as.data.frame(HairEyeColor),
aes(y=Freq, axis1 = Hair, axis2 = Eye, axis3= Sex)) +
geom_alluvium(aes(fill=Eye),
width=1/8, knot.pos = 0, reverse = F) +
geom_stratum(alpha = .25, width=1/8, reverse=F) +
geom_text(stat = "stratum", aes(label = after_stat(stratum)), reverse=F) +
scale_fill_manual(values=c(Brown="brown", Hazel="#E2AC76", Green="darkgreen", Blue="lightblue2")) +
coord_flip() +
theme_minimal()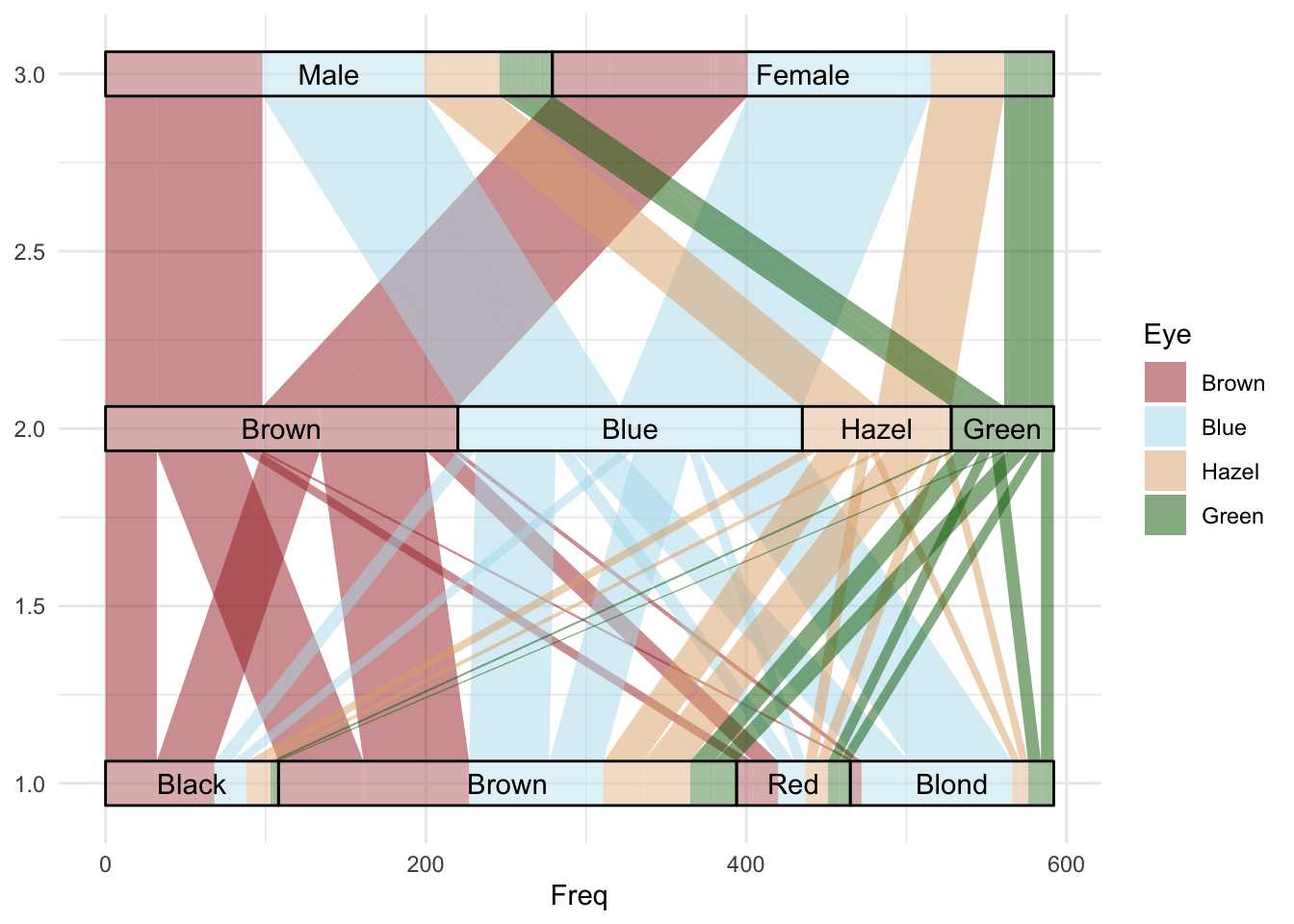
geom_alluvial()은 Sankey plot에서 노드를 그려주고, geom_stratum()은 각 열의 범주를 나타내는 막대를 그려줍니다.
성별 * 머리 색상 * 눈동자 색상에 따른 범주의 분포를 보여주는 그래프가 완성되었습니다.
Long 데이터로 Sankey plot 그리기
이번에는 긴 데이터를 활용해 Sankey plot을 그려보겠습니다. 긴 데이터는 열들의 조합에 따른 범주를 나타내는 넓은 데이터와 달리, 하나의 행이 보통 하나의 경우를 의미합니다. 긴 데이터는 주로 공통된 ID, 그룹 별 값에 따른 데이터를 보여줍니다.
예를 들어보겠습니다. majors라는 데이터를 보면 student 라고 하는 학생 ID가 1번부터 15번 까지 있습니다. 또한 semester는 1학기부터 15학기까지 있는데, 각 학생들의 학기별 curriculum에 대한 데이터를 보여주고 있습니다.
majors$curriculum <- as.factor(majors$curriculum)
ggplot(majors,
aes(x=semester, stratum = curriculum, alluvium=student, fill=curriculum, label = curriculum)) +
geom_flow(stat = "alluvium", lode.guidance = lode_frontback,
color = "darkgrey") +
geom_stratum() +
scale_fill_brewer(type="qual", palette = "Set2")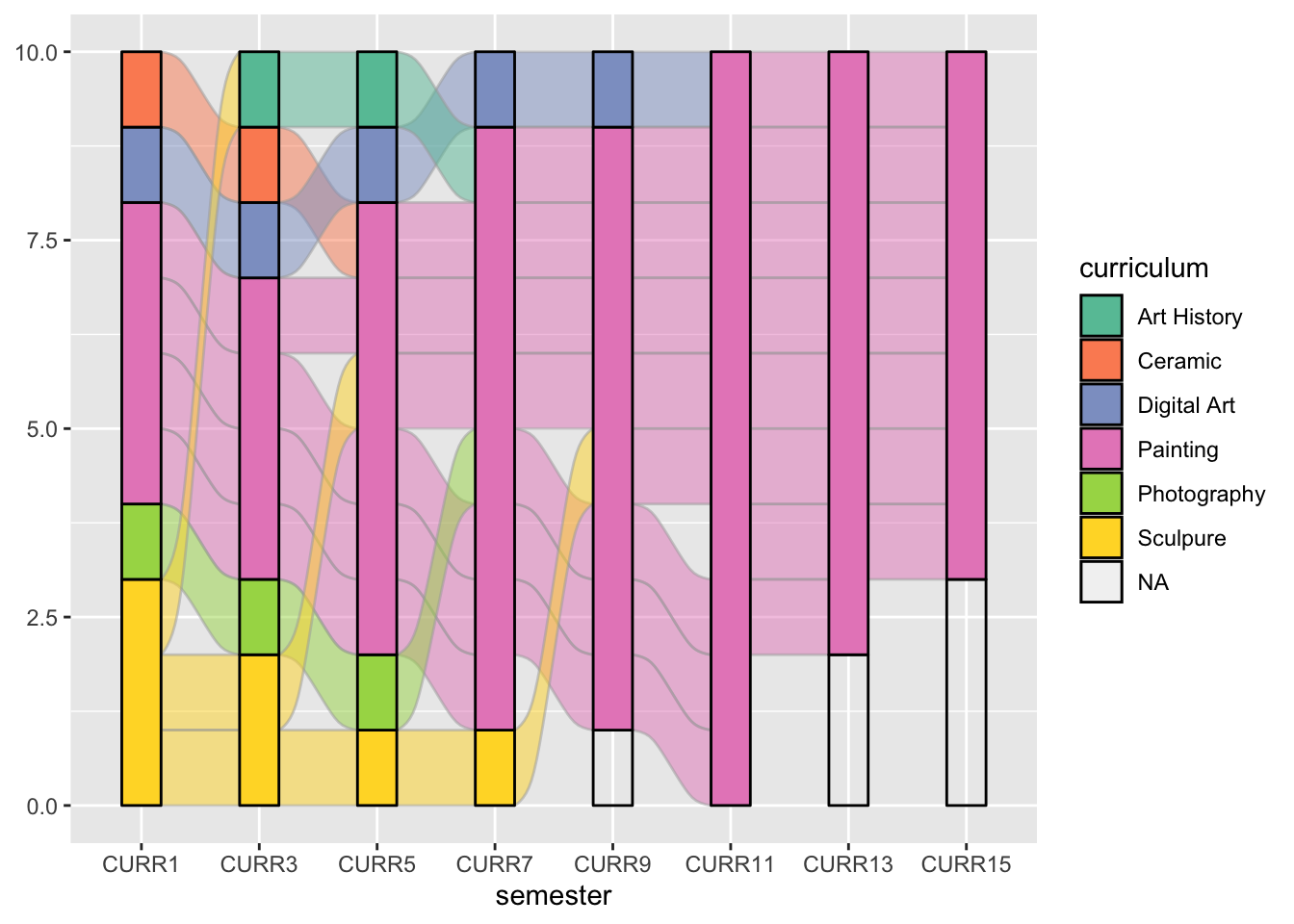
위의 그래프를 통해, 학생들이 학기별로 어떤 커리큘럼을 선택했는지 흐름과 빈도를 알 수 있습니다.
물론 긴 데이터에 빈도가 있는 경우도 이를 활용할 수 있습니다. 마찬가지로 ggalluvial 패키지의 vaccinations 데이터를 이용하겠습니다.
vaccinationsvaccinations 데이터는 RAND American Life Panel 설문 조사 중 세 건을 합친 데이터입니다. 인플루엔자 예방을 위해 백신 접종을 할 의향을 묻고 있는 데이터입니다. Never, Sometimes, Always 등의 응답이 기록되어 있습니다.
# 그래프에서 나타나는 범주 순서 변경 위해
vaccinations$response <- factor(vaccinations$response, levels = rev(levels(vaccinations$response)))
ggplot(vaccinations,
aes(x=survey, y=freq,
stratum = response,
alluvium = subject,
fill = response,
label = response)) +
geom_flow() +
geom_stratum(alpha=.5) +
geom_text(stat = "stratum", size=3) +
scale_x_discrete(expand = c(0.1,0.1)) +
theme_void() +
theme(legend.position = "none")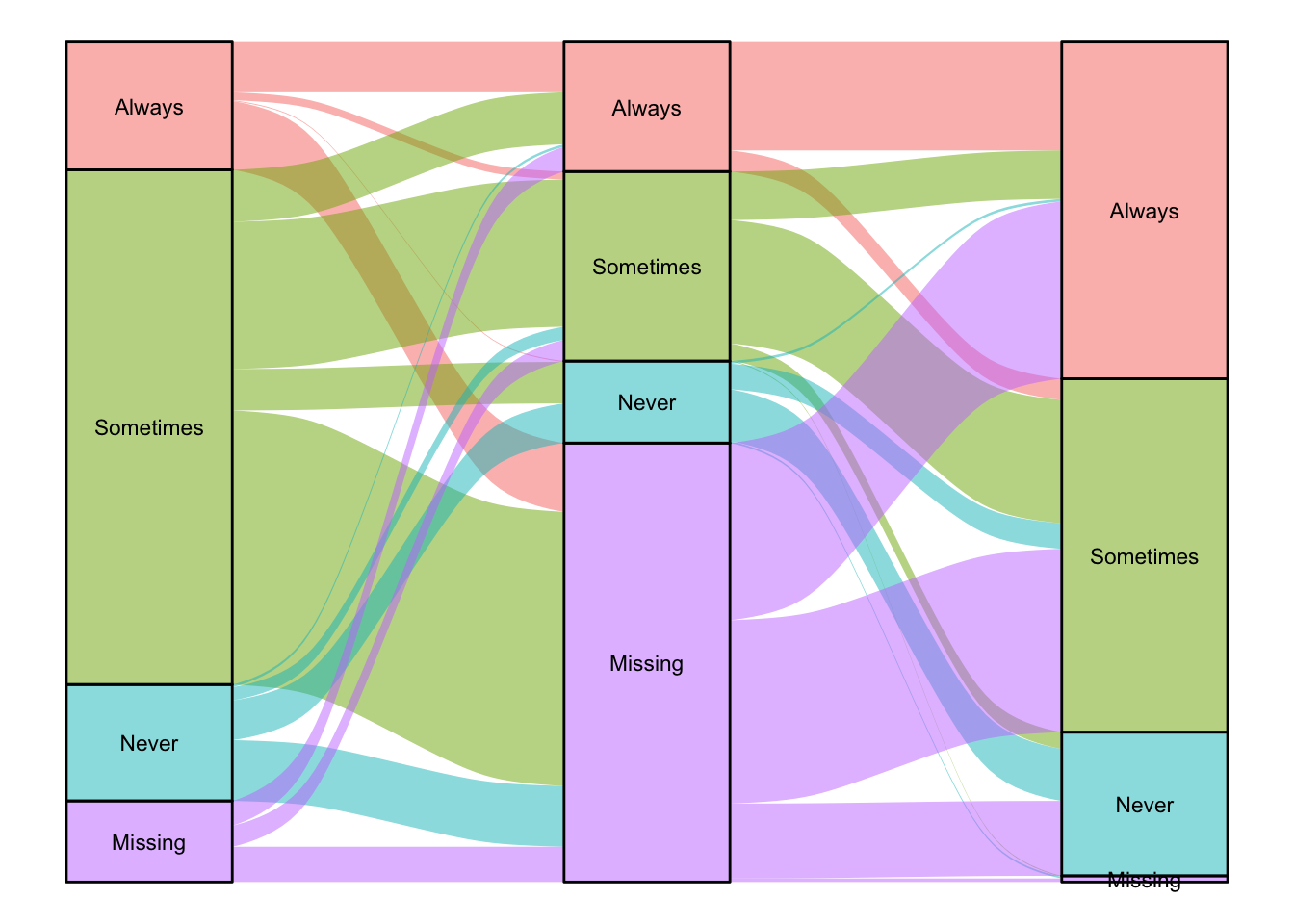
위의 그래프에서 freq는 survey와 response별로 합해져 그래프에 나타나는 것을 알 수 있습니다.